
 专业论文写作-降AI率
专业论文写作-降AI率  Ai应用
Ai应用 Ai资讯
Ai资讯 小说剧本写作
小说剧本写作 小云雀短剧Agent
小云雀短剧Agent Seko漫剧生成
Seko漫剧生成
阿里推出QwenLong-L1-32B:一款用于长上下文推理的LLMai智能软件怎么用

2025年5月26日,阿里巴巴团队发布QwenLong-L1-32B,首个基于强化学习训练的长上下文大推理模型,和DocQA-RL-1.6K数据集(含1600个数学、逻辑、多跳推理类文档问答问题)。其框架通过预热监督微调、课程引导强化学习、难度感知回顾采样机制解决长上下文推理强化学习中训练效率低、优化过程不稳定的挑战,在7个长上下文DocQA基准测试中性能优于Openaiai的软件-o3-mini和Qwen3-235B-A22B,与Claude-3.7-Sonnet-Thinking持平。
")
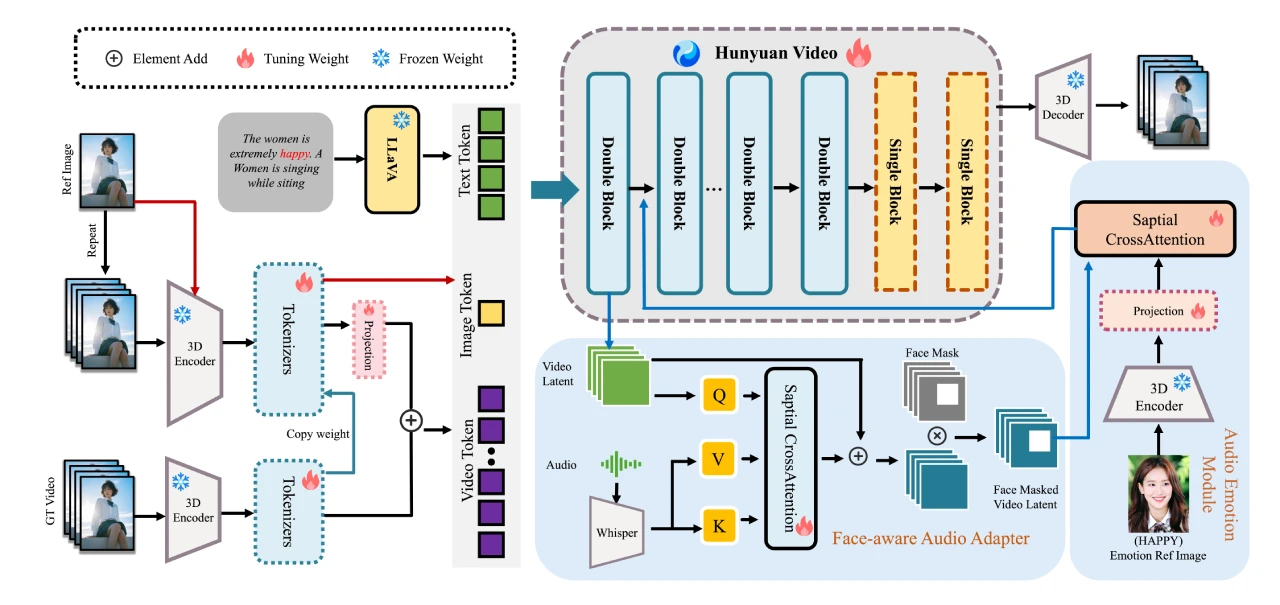
模型框架千问网页版官网入口
核心理念:通过强化学习(RL)将短上下文大规模推理模型(LRMs)适应到长上下文场景中。全免费ai人工智能
主要组成部分:千问网页版官网入口
预热监督微调(SFT)阶段:建立稳健的初始策略。ai指的是什么意思
基于课程的分阶段强化学习技术:稳定策略演化。ai智能软件怎么用
难度感知回顾采样策略:激励策略探索。下载即梦
训练数据ai的软件
使用了名为DocQA-RL-1.6K的专门强化学习训练数据集,包含1600个涵盖数学、逻辑和多跳推理领域的文档问答问题。ai智能软件怎么用
性能表现说的ai
在七个长上下文文档问答基准测试中,QwenLong-L1-32B的表现超过了OpenAI-o3-mini和Qwen3-235B-A22B等旗舰级LRMs,达到了与Claude-3.7-Sonnet-Thinking相当的水平,在当前最先进的LRMs中表现出领先性能。豆包a i生成
实验设计说的ai
构建了一个专门的RL训练数据集DocQA-RL-1.6K,包含1600个文档问答问题,涵盖数学、逻辑和多跳推理领域。ai指的是什么意思
数学推理部分使用了DocMath数据集的600个问题,其中75%用于训练,25%用于评估。ai破解版免费下载
逻辑推理部分通过DeepSeek-R1合成了600个多选题,涵盖法律、金融、保险和生产领域的实际文档。哪个ai比较懂法律
多跳推理部分从MultiHopRAG和Musique中各采样200个例子,强调跨文档推理。哪个ai比较懂法律
在七个长上下文DocQA基准测试上进行了评估,包括2WikiMultihopQA、HotpotQA、Musique、NarrativeQA、Qasper、Frames和DocMath。ai起什么作用
结果与分析ai在线使用
QwenLong-L1-32B在七个长上下文DocQA基准测试中表现优异,超过了OpenAI-o3-mini和Qwen3-235B-A22B等旗舰LRM模型,性能与Claude-3.7-Sonnet-Thinking相当。ai在线使用
在数学推理基准DocMath上,QwenLong-L1-32B的精确匹配和LLM判断准确率达到了85.3%。豆包官网免费使用
在多跳推理基准HotpotQA上,模型的表现达到了87.6%,显著优于现有模型。ai对话聊天系统
项目链接万联摩尔
Github:千问网页版官网入口https://github.com/Tongyi-Zhiwen/QwenLong-L1
Huggingface:豆包a i生成https://huggingface.co/Tongyi-Zhiwen/QwenLong-L1-32B
Modelscope:造梦次元入口https://www.modelscope.cn/models/iic/QwenLong-L1-32B
相关文章ai的软件











- 用户登录